
Overview
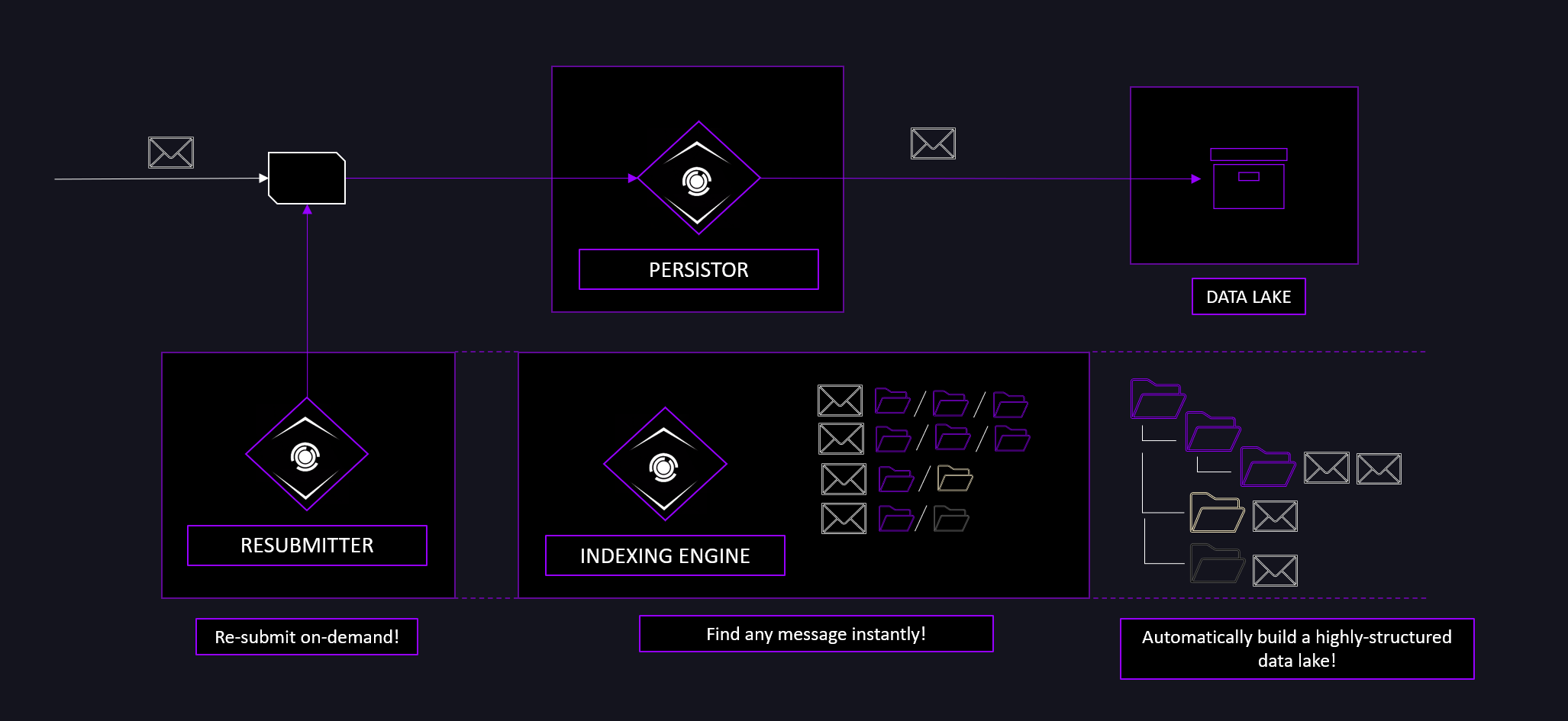
Persistor is a stateless component that efficiently stores messages collected from a message broker topic onto a well-structured data lake. It automatically performs indexation of messages, allowing for their later retrieval and resubmission.
It is designed to eliminate the need for re-submission requests from the original publishers (which is often impossible) and to accelerate the building of well-established data pipelines in general – utilizing the structured storage as a new source of data in itself.
The data can be stored in batches (in Avro format) or as individual messages.
The Persistor is built as a set of interconnected components. A single Persistor deployment consists of multiple Persistor instances (one per topic), with the indexation and resubmission engines being shared, depending on the use case and planned access control.
The main component. Subscribes to a topic and sends messages to persistent storage. It is the only non-optional component.
Supports receiving messages from Google Pub-Sub, Azure Service Bus or Apache Kafka. The available storage options are GCS and ABS
The codebase is modular and can be easily extended to include multiple storage and broker options. Users generally don’t need to interact with it once it is running.
Enables folder structure based on the publish time of a message (coarse or fine-grained, down to the hour). For instance, we would generally expect to find a structure similar to:
{BUCKET/CONTAINER ID}/{SUBSCRIPTION_ID}/{YEAR}/{MONTH}/{DAY}/{HOUR}/{blob_name}.avro
The folder structure also supports the ability of utilizing arbitrary metadata. For instance, if your message features a schemaID field in its metadata, you would be able to categorize your messages based on it, making the structure look as follows:
{BUCKET/CONTAINER ID}/{SUBSCRIPTION_ID}/{SCHEMA_ID}/{YEAR}/{MONTH}/{DAY}/{HOUR}/{blob_name}.avro
(The positioning of this arbitrary metadata can also be configured. Please see the Configuration section for more details.)
If the Indexer component is deployed and enabled, Persistor will formulate a metadata object for each message, containing the information on where each of the received messages is located and their original metadata (headers).
The Indexer component communicates via the original Persistor component via another message broker topic. The Indexer is responsible for consuming the received message metadata and storing it in a NoSQL database (in this specific case, Mongo), to be utilized for finding messages during the exploration and resubmission periods.
The data is exposed via a simple REST API.
The Resubmitter component is built on top of the Indexer component, allowing the user to query the stored metadata to find specific messages (or messages published/received within a specific time period) and trigger their resubmission to a new topic for re-processing.