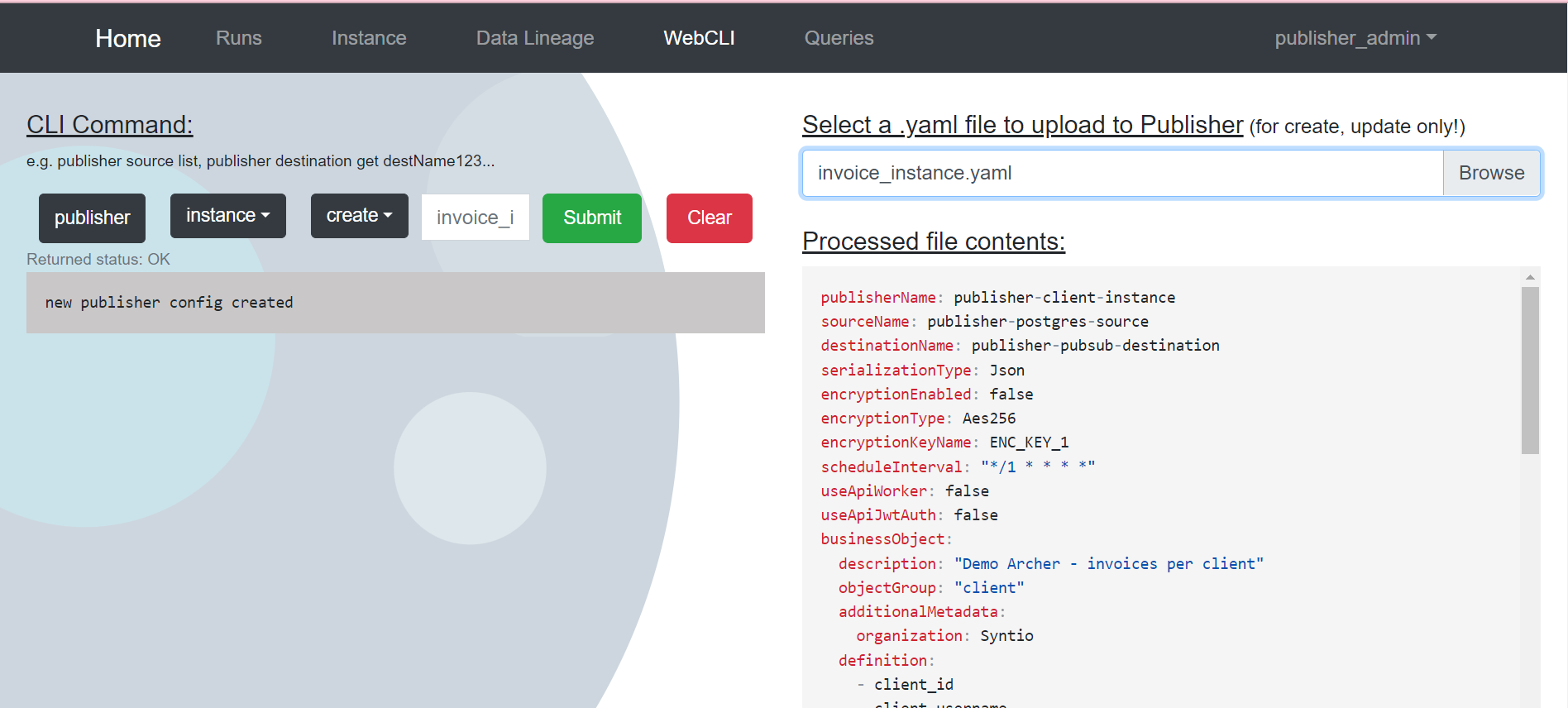
Usage
This page contains all of the information required to further configure the Publisher and ensure proper communication between it and your external resources.
In order to enable Publisher to communicate with the service of your choice, you are required to create and deploy additional secrets in your Kubernetes environment, under the same namespace as Publisher. Google PubSub, for instance, requires the Service Account Key used to connect to your Cloud environment. Kafka, NATS and Pulsar require TLS secrets.
PubSub
| Field Name | Secret Name | Description |
|---|---|---|
key.json |
pubsub-key | Base64-encoded JSON service account key |
Kafka
| Field Name | Secret Name | Description |
|---|---|---|
ca_crt.pem |
kafka-tls-credentials | Base64 encoded Kafka cluster CA TLS certificate |
client_crt.pem |
kafka-tls-credentials | Base64 encoded Kafka user TLS certificate |
client_key.pem |
kafka-tls-credentials | Base64 encoded Kafka user TLS private key |
NATS
| Field Name | Secret Name | Description |
|---|---|---|
ca_crt.pem |
nats-tls-credentials | Base64 encoded Nats cluster CA TLS certificate |
client_crt.pem |
nats-tls-credentials | Base64 encoded Nats user TLS certificate |
client_key.pem |
nats-tls-credentials | Base64 encoded Nats user TLS private key |
Pulsar
| Field Name | Secret Name | Description |
|---|---|---|
ca_crt.pem |
pulsar-tls-credentials | Base64 encoded Pulsar cluster CA TLS certificate |
client_crt.pem |
pulsar-tls-credentials | Base64 encoded Pulsar user TLS certificate |
client_key.pem |
pulsar-tls-credentials | Base64 encoded Pulsar user TLS private key |
When deployed, the Publisher Worker will automatically look for these secrets at the time of running the individual jobs.
Once you are logged into the WebUI, you can add your source, destination and instance YAML files.
- Source defines the source from which Publisher will fetch the data.
- Destination defines to where Publisher will deliver the data (the message broker).
- Instance connects the Source and Destination, and defines the actual publishing job. Both the source and destination may be used in multiple different publishing jobs.
The Source configuration YAML file is used to define the details regarding the source database that the user wants to use as a source of data.
Shared Source Configuration
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| username | String | The username that the user has to provide so that the connection to the desired database can be made. | Yes |
| sourceType | String | Source type represents the type of data source. Can be one of supported database types or API source.Supported database types: Postgres, Oracle, MySql, Db2, SqlServer, Api, Mongo. | Yes |
| sourceName | String | Name of the source configuration. This value needs to be unique upon a single Publisher deployment. Specifying the existing source name when creating a new source resource will result in failure. Also, this name cannot be empty, this is the unique identifier of an existing and active source configuration in the database. | Yes |
| port | Integer | Database port has to be provided so that a connection to the correct source database can be made. | Yes |
| password | String | Database password for the provided username. | Yes |
| parameters* | String | Represents any parameters that a specific database might use for performance purposes. These parameters can be defined in the form of a key: value map. | No |
| host | String | In case of a database source, the database hostname has to be provided so that a connection to the correct source database can be made. In case of an API source, the base API URL has to be provided. E.g., http://exposed-api:3030. The rest of the source API path will be appended based on the query field in the business object. | Yes |
| databaseName | String | Database name that contains source data. | Yes |
Source
| Environment variable name | Value Type | Description | Optimal Value | Required |
|---|---|---|---|---|
| prefetch_rows | Integer | Number of rows to prefetch for each fetch request that results in a roundtrip to the Oracle server. | 1000 | No |
| prefetch_memory | Integer | Sets the memory allocated for rows to be prefetched. | 100 | No |
sourceName: publisher-postgres-source
sourceType: Postgres
host: <LoadBalancer IP address>
port: 5432
databaseName: invoices
username: demo_user
password: demo_password
The Destination configuration YAML file is used to define the details regarding the destination service that the user wants to use as a final destination of data. Every destination includes parameters from the Destination tab. Each destination type has specific parameters that have to be added in the YAML file. These parameters are specified in the other tabs.
Destination
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| destinationName | String | Name of the destination configuration. This value needs to be unique upon a single Publisher deployment. Specifying the existing destination name when creating a new destination resource will result in failure. Also, this name cannot be empty, this is the unique identifier of an existing and active destination configuration in the database. | Yes |
| destinationType | String | Destination type represents the type of destination service that destination configuration will be using. Supported destination types: PubSub, Solace, Kafka, Azure (ServiceBus from version 0.5.1), NatsCore, NatsJetStream. | Yes |
| parameters* | Key-value map | The values specific for some messaging platforms can be defined in the form of a key: value map. | Yes |
Google PubSub
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| ProjectID | String | Name of the Google Cloud Platform project that contains the topic where data will be sent to. | Yes |
| TopicID | String | Name of the Google Cloud Platform topic which will receive sent data. | Yes |
| ByteThreshold | Integer | Suggested value: 150000000 | No |
| CountThreshold | Integer | Suggested value: 400 | No |
| DelayThreshold | Integer | Suggested value: 10000000 | No |
| NumOfGoroutines | Integer | Suggested value: 20 | No |
| MaxOutStandingMessages | Integer | Suggested value: 800 | No |
| MaxOutStandingBytes | Integer | Suggested value: 1000 * 1024 * 1024 | No |
| EnableMessageOrdering | Boolean | Suggested value: false | No |
Kafka
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| BrokerAddr | String | List of Kafka broker endpoints separated by commas, or a single broker. Example: 10.0.42.206:9092 | Yes |
| TopicID | String | Name of the Kafka topic which will receive sent data. | Yes |
| BatchSize | Integer | BatchSize sets the max amount of records the client will buffer, blocking new produces until records are finished if this limit is reached. | No |
| BatchBytes | Integer (Int64) | BatchBytes when multiple records are sent to the same partition, the producer will batch them together. BatchBytes parameter controls the amount of memory in bytes that will be used for each batch. | No |
| Linger | Integer | Linger controls the amount of time to wait for additional messages before sending the current batch. | No |
| TLS | String | Whether encryption should be enabled. Possible values: true or false. Default value is false. | No |
| VerifyServerCertificate | Boolean | If set to true and TLS is enabled, ca_cert.pem file defined in the kafka-tls-credentials secret is used to authenticate the Kafka broker. Default value is false. | No |
| VerifyClientCertificate | Boolean | If set to true and TLS is enabled, client_crt.pem and client_key.pem file defined in the kafka-tls-credentials secret are used to authenticate the client on the broker. Default value is false. | No |
Solace
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| BrokerURI | String | URI to connect to the broker. | Yes |
| TopicID | String | Name of the topic which will receive sent data. | Yes |
| Username | String | The username for the client. | Yes |
| Password | String | The password for the client. | Yes |
| Qos | Integer | Level of quality of service. Default value is 1. | No |
Azure
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| ConnectionString | String | A connection string includes the authorization information required to access data in an Azure Storage account at runtime using Shared Key authorization | Yes |
| TopicID | String | Name of the topic which will receive sent data. | Yes |
Pulsar
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| ServiceURL | String | URL to connect to the brokers. | Yes |
| TopicID | String | Name of the topic which will receive sent data. | Yes |
| TLS | String | Whether encryption should be enabled. Possible values: true or false. Default value is false. | No |
| VerifyServerCertificate | Boolean | If set to true and TLS is enabled, ca_cert.pem file defined in the pulsar-tls-credentials secret is used to authenticate the Pulsar broker. Default value is false. | No |
| VerifyClientCertificate | Boolean | If set to true and TLS is enabled, client_crt.pem and client_key.pem file defined in the pulsar-tls-credentials secret are used to authenticate the client on the broker. Default value is false. | No |
| ConnectionTimeout | Integer | ConnectionTimeout is the timeout for the establishment of a TCP connection in seconds. Default value is 5 seconds. | No |
| OperationTimeout | Integer | OperationTimeout is the timeout for creating the publisher. Default value is 30 seconds. | No |
| SendTimeout | Integer | SendTimeout is the timeout for a published message to be acknowledged by the broker. Default value is 30 seconds. | No |
| MaxConnectionsPerBroker | Integer | MaxConnectionsPerBroker is the max number of connections to a single broker that will be kept in the pool. Default value is 1. | No |
| DisableBlockIfQueueFull | Integer | DisableBlockIfQueueFull controls whether publishing blocks if producer’s message queue is full. Default value is false. | No |
| MaxPendingMessages | Integer | MaxPendingMessages specifies the max size of the queue holding messages waiting an acknowledgment from the broker. Default value is 1. | No |
| MaxReconnectToBroker | Integer | MaxReconnectToBroker specifies the maximum retry number of reconnectToBroker. Default value is nil. This means the client retries forever. | No |
NATS
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| URL | String | URL to connect to the brokers. | Yes |
| Subject | String | Name of the subject which will receive sent data. | Yes |
| MaxPending | Integer | MaxPending sets the maximum outstanding async publishes that can be inflight at one time. Default value is 512. | No |
| TLS | String | Whether encryption should be enabled. Possible values: true or false. Default value is false. | No |
| VerifyServerCertificate | Boolean | If set to true and TLS is enabled, ca_cert.pem file defined in the kafka-tls-credentials secret is used to authenticate the Kafka broker. Default value is false. | No |
| VerifyClientCertificate | Boolean | If set to true and TLS is enabled, client_crt.pem and client_key.pem file defined in the kafka-tls-credentials secret are used to authenticate the client on the broker. Default value is false. | No |
destinationName: publisher-pubsub-destination
destinationType: PubSub
parameters:
ProjectID: <your project id>
TopicID: <your topic>
The Instance configuration YAML file is used to define the job specifics. This is the central type of configuration and its creation and validation depend on the existing active source and destination configurations. The Instance configuration YAML file is fairly minimalistic in approach, but allows enough flexibility to fine-tune the requirements of your publishing job.
Here, we define the query the data will be fetched with, how it will be formatted, serialized, encrypted and, finally, published.
For ease of understanding, we will split the file into three distinct sections:
- The Instance portion, defining how the source and destination should connect.
- The Fetcher portion, defining how the data should be pulled from the source.
- The Business object portion, defining how the data will be transformed directly prior to publishing.
Instance configuration
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| publisherName | String | Name of the Publisher instance. This value needs to be unique upon a single Publisher deployment. Specifying the existing publisher name when creating a new Publisher instance will result in failure. Also, this value cannot be empty. | Yes |
| sourceName | String | Name of the existing source configuration that this Publisher instance will use for setting up the connection to source. Specifying a nonexistent source name will result in failure in the validation process. | Yes |
| destinationName | String | Name of the existing destination configuration that this Publisher instance will use for setting up destination details. Specifying a nonexistent destination name will result in failure in the validation process. | Yes |
| serializationType | String | Name of the supported serialization type to be used in Publisher instance. Users can define only one of the possible serialization types. Supported serializations: Avro, Json | Yes |
| encryptionEnabled | Boolean | A boolean flag indicates if encryption will be used in the Publisher instance. | No |
| encryptionType | String | If the flag above is set to true, it is expected of the user to specify the encryption type that will be used in the Publisher instance. Users can only input one type. Supported encryptions: Aes256 | No (Yes if encryptionEnabled is “Yes”) |
| encryptionKeyName | String | Refers to a name of a variable which the user is using to represent his encryption key, so the user does not input the key itself but only the name of that key. | No (Yes if encryptionEnabled is “Yes”) |
| scheduleInterval | String | A sleeping mechanism for the Publisher. Since Publisher supports scheduled running, this field represents how often the user wants Publisher to do a single run (fetching and publishing of data). This needs to be a cron-type expression. Meaning, the user must set the recurring interval in which Publisher will run (e.g. each minute of each hour */1 * * * *), meanwhile it waits. Default value: null. | Yes (only if fetchSkippedScheduledIntervals is true) |
| schema | String | Since one of the Publisher’s main components and features is serialization, a schema is required which the user can provide. If the user does not provide one, Publisher will generate one, use it and store it for future purposes. | No |
| scheduledStartTime | String | The field a user can use to schedule when Publisher will start its initial running. The expected format of the input value is the date of the wanted publisher start (e.g. 2022-01-01 00:00:00), until then Publisher will sleep. This is a bonus feature meaning that by default this value is set to null and that the publisher will start its process immediately upon successful creation of publisher configuration. | No |
| fetcherConfig | Key-value map | Used when the instance fetches from an API source. | Yes |
| useApiWorker | Boolean | Used when the instance fetches from an API source. | No |
| useApiJwtAuth | Boolean | Used when the API source requires JWT authentication to access data. | No |
Fetcher configuration
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| useNativeDriver | Boolean | This boolean flag indicates if the user wants to use native Golang drivers for fetching which are faster but behave inconsistently or the implemented Java fetcher which is more stable but slower. | No |
| UseReflectTypeFetch | Boolean | Used when native Golang drivers are being used for fetching. If true, fetched data types will be mapped to the ones in the database and therefore will be slower. | No |
| ReturnCsv | Boolean | CSV format will be returned instead of JSON from the Java Fetcher. | No |
| initialFetchValue | Boolean | Defines the lower bound of the first, initial fetch period in the WHERE condition clause. For the first run ever, Publisher will do a greater-or-equal ( >= ) condition on it. | No |
| endFetch | String | Since queries in Publisher are executed on specific time intervals, this represents the date which when reached will stop the fetching process and therefore the Publisher itself. By default it is empty but the user can input the date he desires (e.g. 2010-01-01 00:00:00). | No |
| fetchingThreadsNO | Integer | The number of parallel threads that will split the query fetch period in order to speed-up row-fetching. | No |
| apiFetchFromParam | String | The query parameter in the API URL which represents the date from which the data is fetched from. E.g., with date_from apiFetchFromParam: http://exposed-api:3001?date_from= |
Yes (only if useApiWorker is set to true) |
| apiFetchToParam | String | The query parameter in the API URL which represents the date until which the data is fetched to. E.g., with date_to apiFetchToParam: http://exposed-api:3001?…&date_to= |
Yes (only if useApiWorker is set to true) |
| apiTimeLayout | String | The format of the timestamp value that the Publisher appends to apiFetchFromParam and apiFetchToParam. E.g., 2006-01-02 15:04:05. | Yes (only if useApiWorker is set to true) |
| apiQueryParams | String | Map of key-value pairs containing static query parameters for the API URL. | No |
| apiHeaderParams | String | Map of key-value pairs containing header information for the API request to fetch data. | No |
| apiJwtAuthPath | String | The path which will be appended to the host field in the source configuration. This URL will be used to generate the JWT. | Yes (only if useApiJwtAuth is set to true) |
| apiJwtAuthBody | String | Map of key-value pairs containing the body for the POST request to generate the JWT. | Yes (only if useApiJwtAuth is set to true) |
| apiJwtAuthHeaders | String | Map of key-value pairs containing header information for the API request to generate the JWT. | No |
| queryIncrementType queryIncrementValue | String Integer | The two parameters as a pair determine the upper bound of the fetch period. Publisher will automatically apply the strictly lower condition ( < ) and calculate the upper bound by using the formula: last successful fetched period + queryIncrementValue queryIncrementType , for example: 2010-03-01 00:00:00 + 1 year => < 2011-03-01 00:00:00 2010-03-01 00:00:00 + 3 month => < 2010-06-01 00:00:00 2010-03-01 00:00:00 + 5 minute => < 2010-03-01 00:05:00 Supported types for queryIncrementType : year, month, day, hour, minute, second | Yes |
| dataSeparatorChar | String | This value is taken into account when the Publisher is using Java Fetcher in his fetching process. Indicates the separating sign that will be used when separating fetched data. | No |
| fetchSkippedScheduledIntervals | Boolean | Used when the user wants the Publisher instance to catch up to current time if it stopped for some reason when it is running in scheduled mode. | No |
Business object
| Environment variable name | Value Type | Description | Required |
|---|---|---|---|
| description | String | Used for describing and clarifying the business objects. | No |
| objectGroup | String | Can be filled out if this business object belongs to a certain predefined group of business objects. Used for easier searching. | No |
| additionalMetadata | Key-value map | Any additional metadata that the user wants to provide with the business object. In the form of a key: value map. | No |
| batchMode | String | The type of database row batching. When set, the rows that are fetched from the database are batched. Each batch of rows is then formatted into a message (if groupElements is defined) by the definition. If groupElements is not defined, each batch is returned as a message.The batches are consisted of a maximum of batchSize rows. Batches can be smaller if there is no more data in the Publisher run to fill the batch.maxRowCount. Batch mode batches database rows by the batchSize number of rows, or less. maxEstimatedSizeInBytes batch mode batches database rows by the batchSize memory size of data in bytes, or less. | No |
| batchSize | Integer | The size of a batch used when a batchMode is specified. | Yes (only if batchMode is specified) |
| definition | String | Defines message format. Used for detailing business object structure and fields. Needs to be defined when groupElements are set (grouping is enabled). Database rows that are grouped by the groupElements values into a single business object are formatted into a single message by the definition. Important note: To prevent data loss, every column in the definition that is not the same for each grouped database row in the business object, should be in an array of values (arrayElements). | No |
| arrayElements | String | Definition elements that will be created and treated as arrays. Those elements need to contain non-repeating columns which can then be treated as array elements (each record that has the same grouping keys will have non-repeating values stored as a single element of array node). | No |
| groupElements | String | Column list which indicates the values which need to be the same for multiple fetched dataset rows in order for them to be grouped into a single message structure that will fit the specified definition (business object). If groupElements is not defined (grouping is disabled), the fetched database rows are returned as messages without additional formatting. In that case, the definition is not used. | No |
| keyElements | String | List of columns whose values will be used to create a single value. This value will be one out of the two values (id_elements) that can uniquely mark every record sent to some messaging platform. The values are concatenated with an underscore delimiter. The value extracted using keyElements is set as the key for the message sent to the broker. When groupElements is not defined (grouping is disabled), and batchMode is specified (batching is enabled), the key elements are extracted for the first and last row in the batch and concatenated with a semicolon delimiter. In that case, the recommended value for keyElements is the timestamp column used in the query (the rows are sorted by the timestamp) |
No |
| idElements | String | List of columns whose values will be used to create a single value. This value will be one out of the two values (key_elements) that can uniquely mark every record sent to some messaging platform. The values are concatenated with an underscore delimiter. When groupElements are not defined (grouping is disabled), and batchMode is specified (batching is enabled), the key elements are extracted for the first and last row in the batch and concatenated with a semicolon delimiter. | No |
| query | String | Users must enter a valid SQL SELECT query (WITH CTE is also supported) used to fetch database rows. The query must select all columns that will be used in the business object definition. The query must have placeholders variables for a timestamp column used to fetch data in uniform timestamp intervals per Publisher run. Publisher will automatically replace the variables with actual timestamps calculated based on configuration. E.g., SELECT invoice_id, cost FROM invoices WHERE creation_date >= to_timestamp({{ .FetchFrom }}, ‘YYYY-MM-DD HH24:MI:SS’) AND creation_date < to_timestamp({{ .FetchTo }}, ‘YYYY-MM-DD HH24:MI:SS’); | Yes |
publisherName: publisher-demo
sourceName: publisher-postgres-source
destinationName: publisher-pubsub-destination
serializationType: Avro
encryptionEnabled: false
businessObject:
description: "Demo Publisher - invoices for client"
objectGroup: "invoices-client"
additionalMetadata:
organization: Syntio
definition:
- client_info:
- client_id
- client_username
- client_location
- invoice_info:
- invoice_id
- creation_date
- due_date
- fully_paid_date
- invoice_items:
- invoice_item_id
- quantity
- total_cost
groupElements:
- client_id
- invoice_id
arrayElements:
- invoice_items
keyElements:
- client_id
- invoice_id
idElements:
- client_id
query: |
SELECT
invoice_id,
client_id,
client_username,
client_location,
creation_date,
due_date,
fully_paid_date,
invoice_item_id,
quantity,
total_cost,
billing_item_id
FROM demo_invoices
WHERE
creation_date >= to_timestamp({{ .FetchFrom }},'YYYY-MM-DD HH24:MI:SS')
AND
creation_date < to_timestamp({{ .FetchTo }}, 'YYYY-MM-DD HH24:MI:SS');
fetcherConfig:
fetchingThreadsNO: 3
queryIncrementType: HOUR
queryIncrementValue: 12
initialFetchValue: 2020-01-01 00:20:00.000
useNativeDriver: true
Below is the screen you will be greeted with after first logging into the Publisher Web UI.
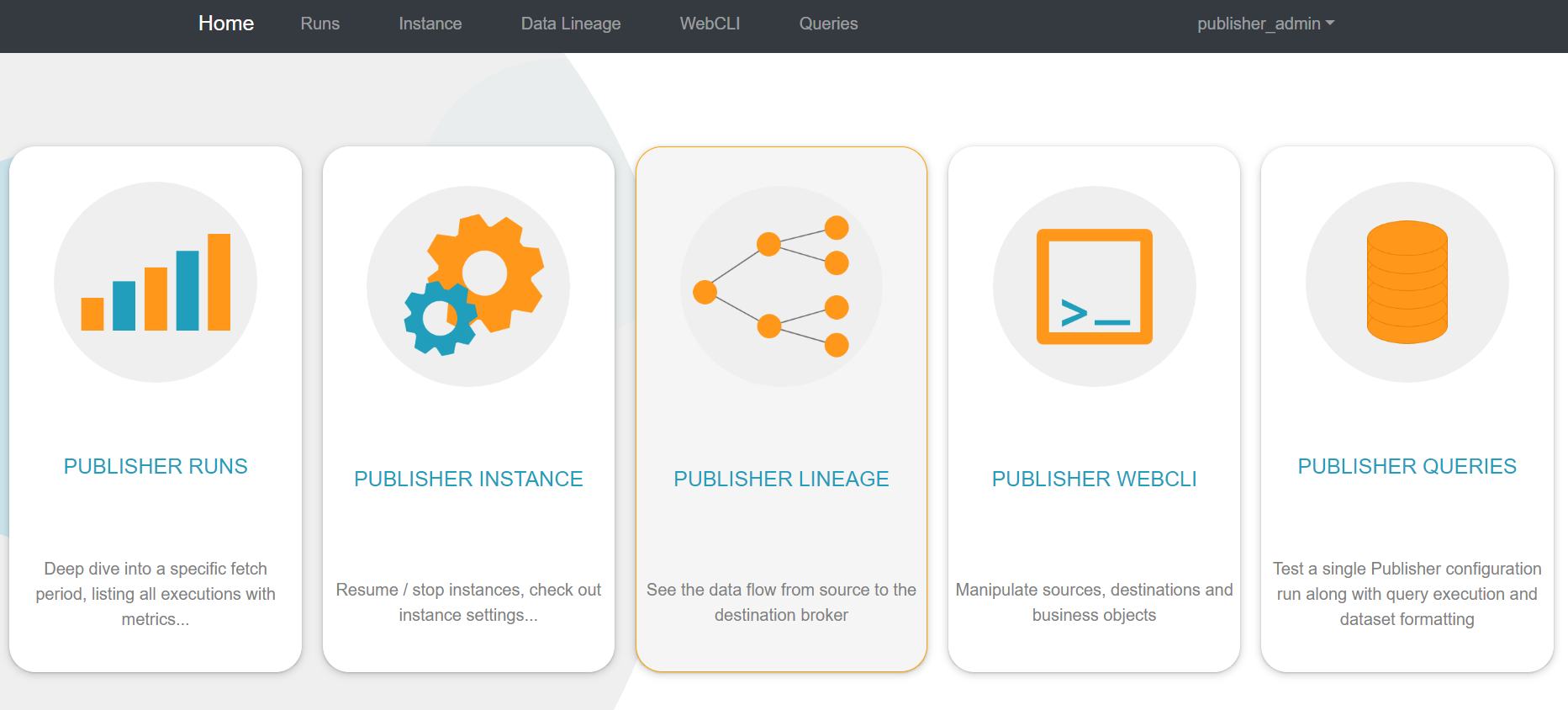
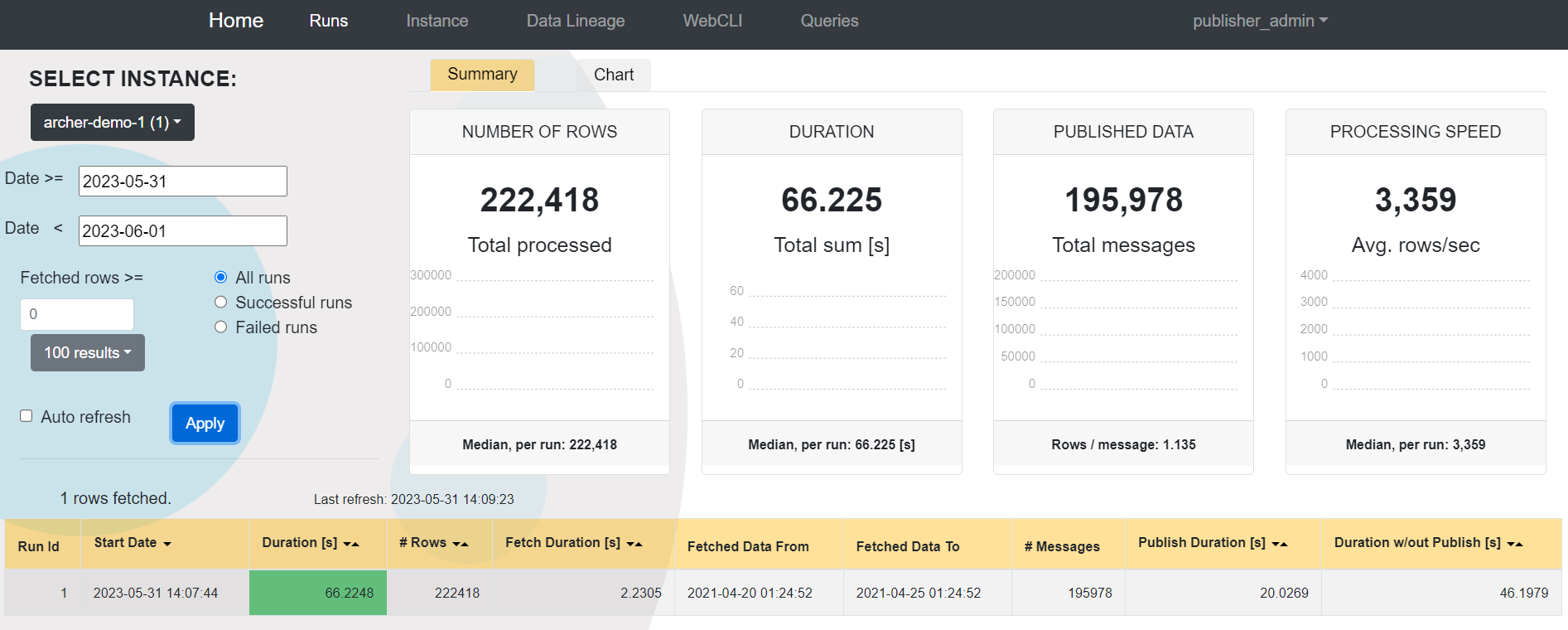
Publisher runs - statistical information about the execution of each instance.
Publisher Instances - overview of Publisher’s instance configurations, providing the ability to start and stop instances as required.

Publisher Lineage - data origin, what happens to it, and where it moves over time.

Publisher queries - testing Publisher instance configuration with verbose error messages. You can view the efficiency of query as well as a sample of the data obtained.
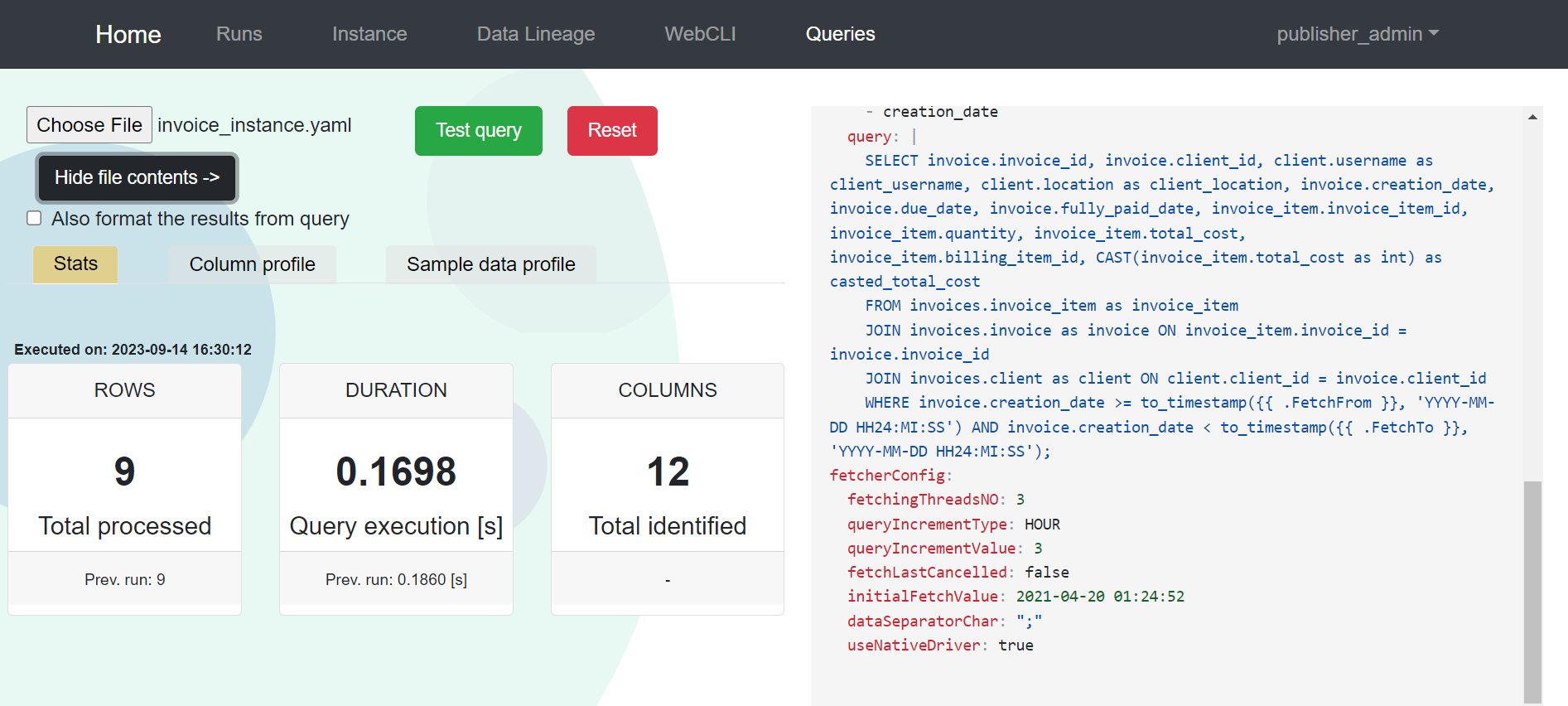
WEB CLI - update and process YAML files to update sources, destinations, configuration. First, add source YAML, then destination and then instance. You can add, update and delete your configuration.